Milvus, A Purpose-Built Vector Data Management System
Milvus: A Purpose-Built Vector Data Management System
Author: Jianguo Wang ,et al.
vector database
A new type of database specialized in storing and querying vector data.
-
Traditional relational databases: precise attribute-based searches
-
Vector database: approximate similarity-based vector searches: find the k-nearest vectors to the query.
Background & Motivation

Challenges
Current works have the following limitations:
- They are not full-fledged systems and cannot handle large amount of data
- They cannot easily handle dynamic data while ensuring fast real-time searches
- They do not support advanced query processing
- They are not optimized for heterogeneous computing architecture with CPUs and GPUs
Milvus
Milvus: a purpose-built vector data management system for managing large-scale and dynamic vector data to enable data science and AI applications.
Milvus incorporates query processing, indexing and storage management and CPU-GPU codesign into the whole system, successfully addressing the previous issues.
Overall Architecture of Milvus
Query Processing
Support of query types:
- Vector Query (1 vector)
- Attribute Filtering (1 vector + n attribute constraints)(Advanced Query)
- Multi-vector Query (n vectors)(Advanced Query)
Support of similarity functions:
- Euclidean distance
- Inner product
- Cosine similarity
- Hamming distance
- Jaccard distance
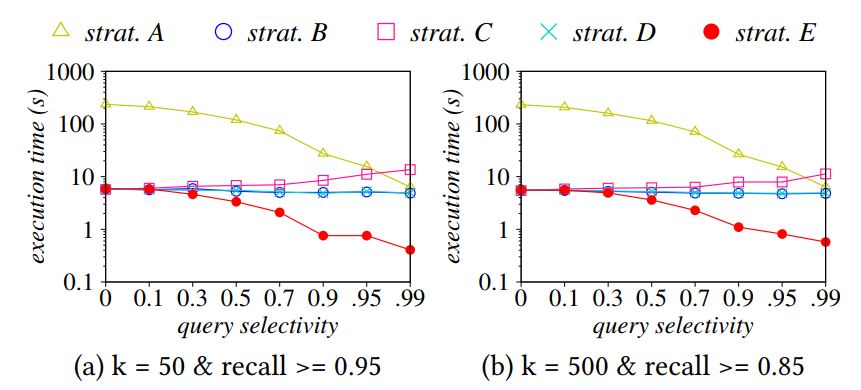
Attribute Filtering
-
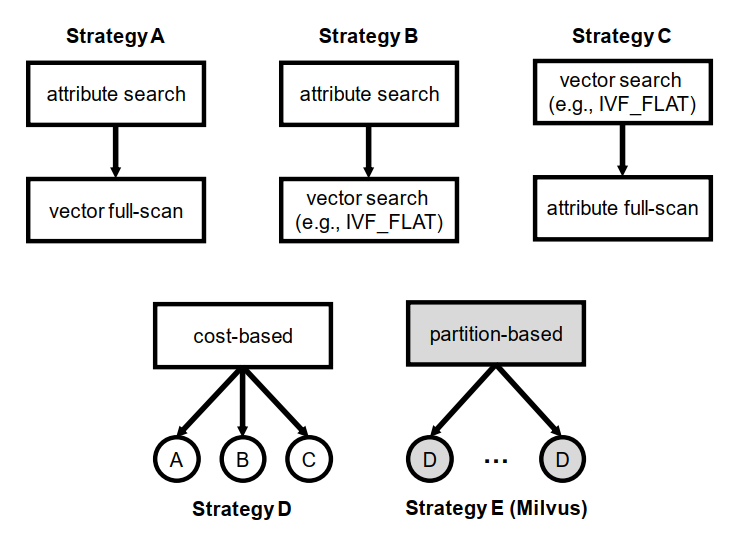
A: ①obtain the satisfied vectors②fully scann them
-
B: ①obtain the satisfied vectors②use bitmap to find the answer
-
C: ①obtain more than k results②fully scan and find those satisfy the attribute constraint
-
D: estimate the cost of A,B,C and find the best one
-
E (Milvus): Partition-based filtering
- Create partitions for data
- Maintain min-max indexes for different partitions
- Skip the partitions whose range of attribute does not overlap with the queries’
- Find the overlapping partitions, and apply strategy D(cost-based) within each partition
Multi-vector Queries
-
For decomposable similarity functions: Use aggregate functions to concentrate the vectors and find the k nearest neighbors based on the concentrated vector (vector fusion)
-
For indecomposable similarity functions:

Indexing (Querying)
-
Quantization-based Indexing: (Quantization: represent vectors with a codebook. First find n nearest clusters to q, then use the indexing to search within these clusters.)
-
IVF_FLAT
-
IVF_SQ8
-
IVF_PQ
-
-
Graph-based indexing:
- HNSW
- RNSG
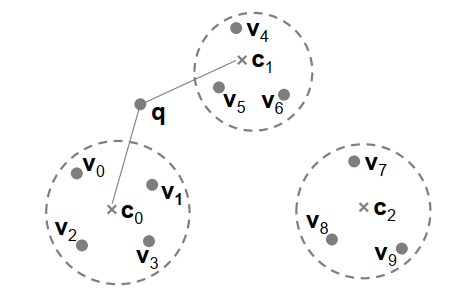
Vector and Attribute Storage
To facilitate query processing, Milvus stores vectors and attributes in a columnar fasion.
- Vectors: different vectors of entities are stored together correspondingly.
- Attributes: <attr value, row ID> pairs + skipping indexes (min-max) for pages

Milvus also relies on LRU-based buffer and supports multiple file systems.
Optimizations for Heterogeneous Computing
How to find the top k similar vectors for multiple queries efficiently?
- CPU-oriented Optimization
- GPU-oriented Optimization
- CPU-GPU codesign
CPU-oriented Optimization
-
Faiss leveraged OpenMP to realize multi-threading. Each thread process a query at a time. Two issues:
- High cache-missing rate (requires to stream the entire data into caches, cannot reuse)
- Cannot fully exploit cores when query number is small
-
Milvus assign threads to data vectors instead of query vectors to address the 2nd issue.
- Divide the queries into blocks s.t. each query block and its heaps can fit in L3 cache.
- Results are managed in heaps. To obtain the final results, merge the result.
- Milvus is also capable of automatically choosing SIMD instructions for functions.
GPU-oriented Optimization
- Faiss: k<=1024 because of the limit of memory
- Milvus: divide k into different rounds, each round expanding the obtained result set until reaches the required number.Faiss: must set the number of GPUs in advance; dynamic segment-based scheduling that assign search tasks to available devices
CPU-GPU Co-design
-
Limitations of Faiss (IVF_SQ8):Low PCIe bandwidth utilization (1 bucket per time)Data transfer makes GPU computing unbeneficial
-
Milvus (SQ8H):High bandwidth utilization (Multiple buckets loaded per time)Assess the running mode (GPU-only or hybrid) based on the batch size

Applications
- Recommender System
- Image Recognition
- Chemical Structure Analysis
- etc.
Evaluation
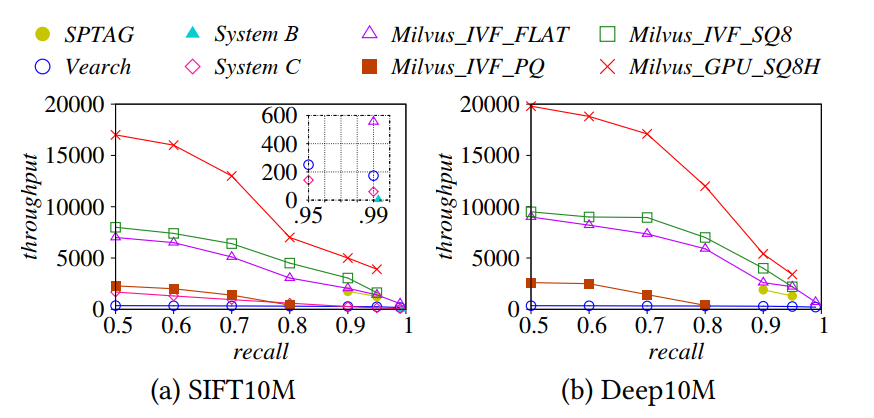
Evaluation (Comparing with other systems)
- 10M vectors from SIFT1B and Deep1B
- 10000 random queries