SpotServe, Serving Generative Large Language Models on Preemptible Instances
SpotServe: Serving Generative Large Language Models on Preemptible Instances
Author: Xupeng Miao, et al.
Background
Generative LLM
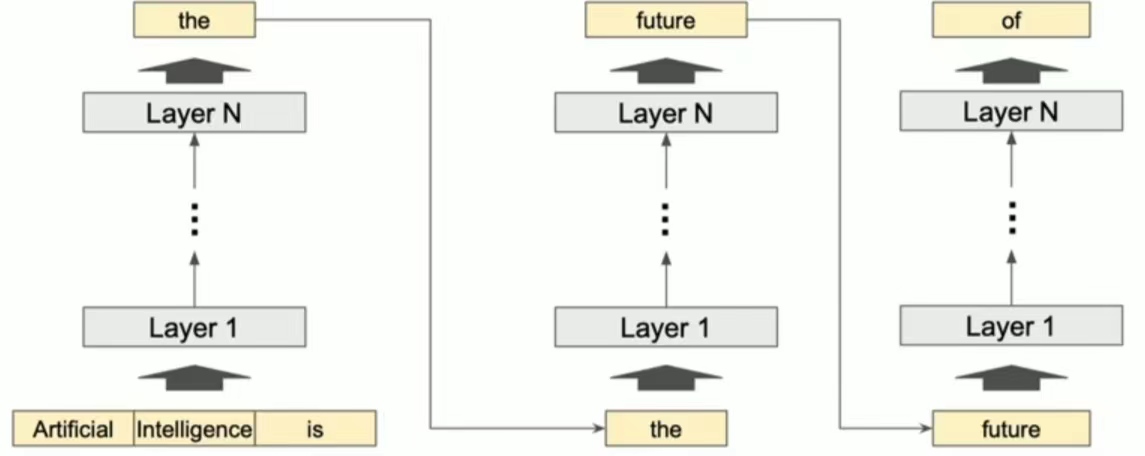
-
Input: tokens;
-
Output: token sequence
-
Stops when: output reaches maximum length/ending token
Two types of GPU Instances
-
On-demand GPUs:
- Expensive
- Use anytime you need
-
Preemptible GPU Instances (e.g. Spot Instances):
- Cheap (run on spare capacity)
- Might be Preempted anytime
- Offers a grace period after preemption to complete currently running tasks
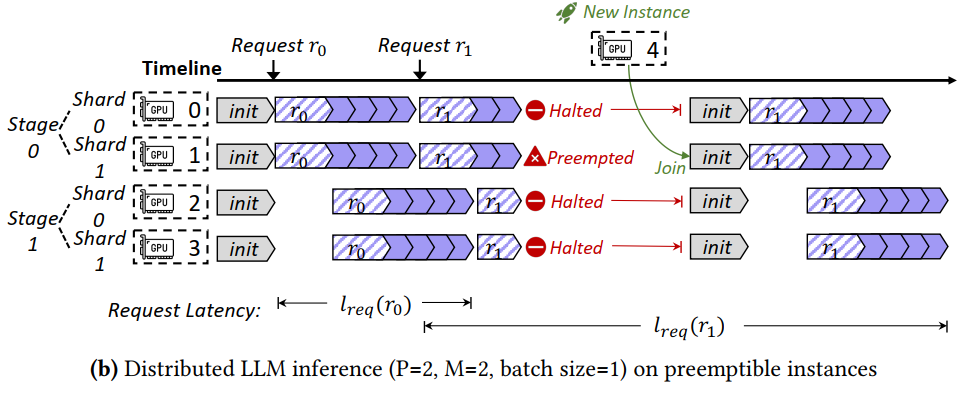
Challenges
-
The number of available preemptible instances changes frequently => Dynamic reparallelization for optimized serving performance
-
Restarting LLM results in great overhead of reloading parameters => Find the optimal migration strategy that minimize the cost
-
Grace periods may not be long enough for finishing current request
-
The reduction of throughput during this process might lead to accumulation of subsequent requests
SpotServe
Overview
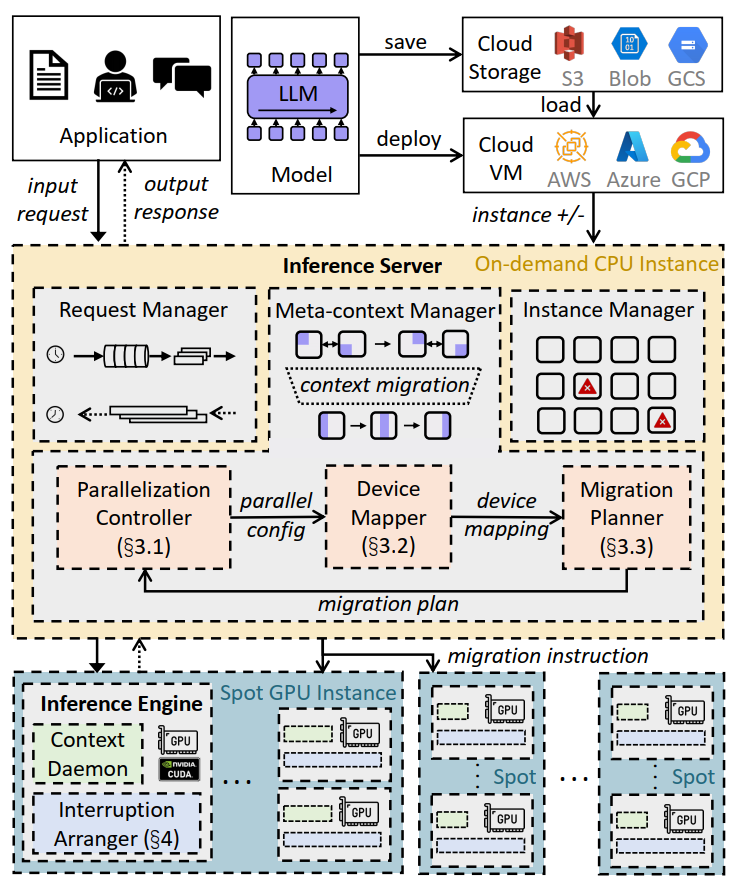
- Request Manager: handle requests, partition into batches, assign them to instances, send output to users
- Instance server: monitor the preemption and acquisition of instances
- Meta-context manager: schedule the context migration between GPU instances (parameters, outputs, etc.)
Meta-context Manager
Parallelization Controller
Parallelization Configurations:
- D: Data Parallelization: partition requests and assign them to different pipelines
- P: Pipeline model parallelization: run different stages of a inference process simultaneously (like pipeline in CPU)
- M: Tensor model parallelization: split the model into shards and assign to different GPUsParallel
- Configuration C = (D, P, M)
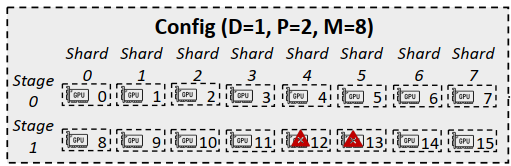
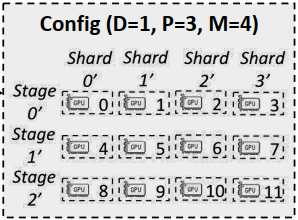
Configuration Optimizer

If there is a configuration such that the throughput is larger than the request arrival rate, then choose the configuration that has minimum inference latency while making sure the throughput is larger than arrival rate. Otherwise, find the C for maximum throughput.
After adjusting the configuration, allocate or free instances.
Offline process => low latency
What do we have now?
- We now have a configuration for the next step.
- However, we only decided the parallelization structure.
- How should us decide how to map the physical instances to logical positions?
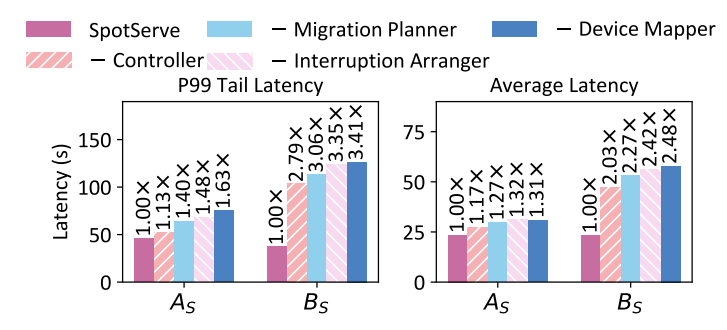
Device Mapper
- Goal: find the matching strategy that maximize reusable context (i.e., edge weight sum)
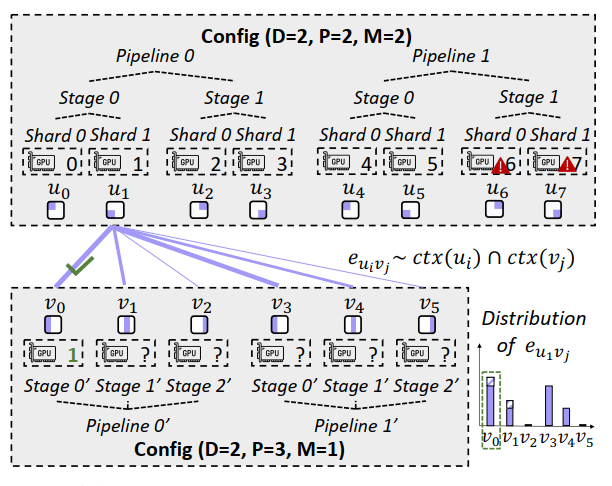
- Approach: *KM (*Kuhn-Munkres) Algorithm for Bipartite Graph Maximum Weight Matching

edges: e(u, v) indicates reusable parameters and caches when mapping GPU u to position v.
Migration Planner

- From front layers (0, 1) to back layers (N), find the layers whose context do not exceed the buffer size and prioritize migration of these layers.
- For other layers, add them to the sequence by the order of instance buffer memory usage
- After we have the sequence, sequentially migrate the layers in this sequence. If all layers of a specific stage is migrated, start running this stage.
Just-in-time Arrangement
What should we do if we receive a preemption/acquisition notification while there are still requests running/waiting?
- Immediately suspend and migrate? => high inference latency
- Finish all requests? => no enough time for migration
- SpotServe: for preemption, maximize token generation (since migration happens during the grace period); for acquisition, minimize token generation when exploiting the whole grace period (since migration happens after the grace period)
Experimental Evaluation
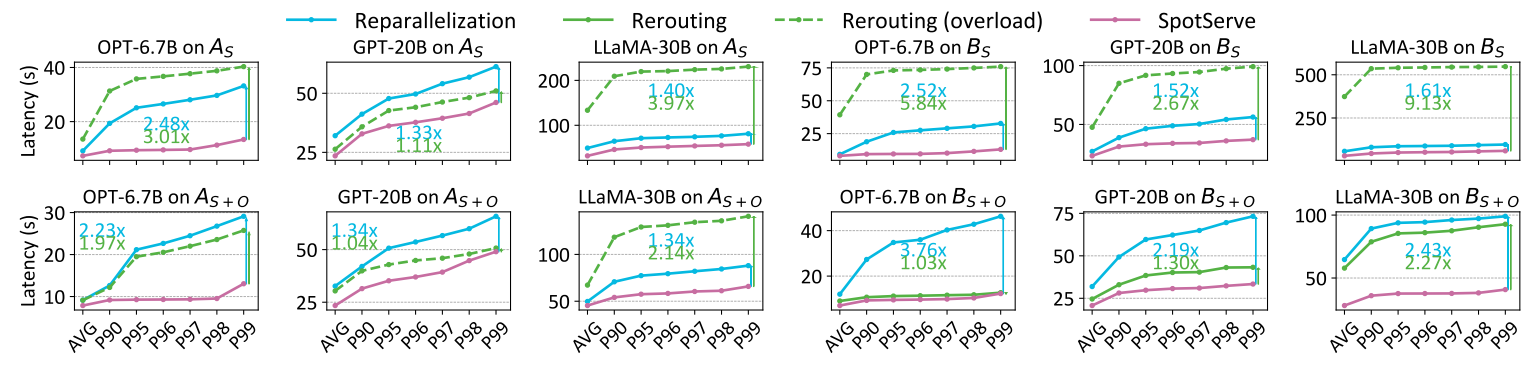
Comparison
-
Stable workload
-
P99: latency at the 99th percentage (99% latency <= this value)
-
Baselines: FasterTransformer (reparallelization but no cocntext migration, rerouting with pre-defined config)
-
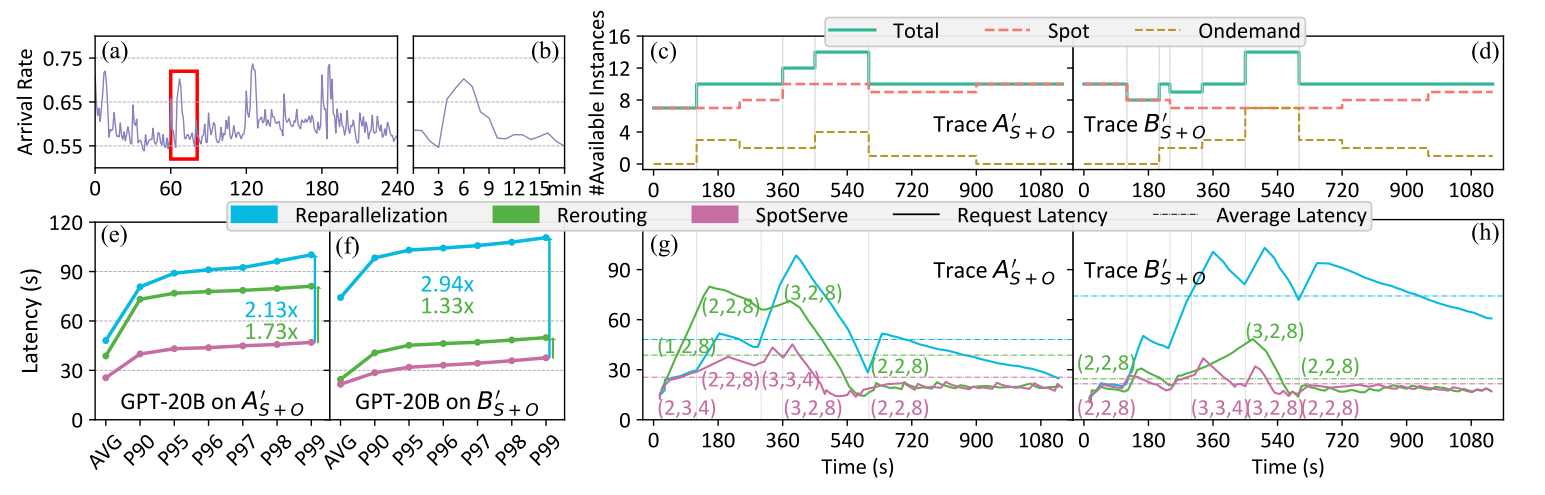
Fluctuating Workload