CUDA编程 1. GPU架构和入门程序
GPU架构与CUDA编程
了解GPU架构
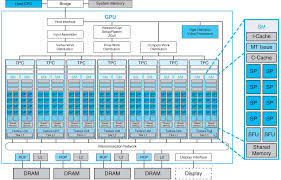
硬件元件:CUDA Core, SM
NVidia GPU迭代了多种架构,有Tesla、Fermi、Maxwell、Kepler、Turing等,但是各种架构的核心结构是相似的。
我们都知道GPU善于做大量并行的、简单的运算,比如说矩阵运算。这就与GPU的架构有关了。CPU的架构注重复杂的控制逻辑和单条指令的低延迟(加入分支预测、冒险等),而GPU则注重高吞吐率,每个计算单元相对简单,由多个计算单元同时进行计算来达到极高的吞吐量。
这种执行模型叫做SIMT(Single Instruction Multiple Threads),即单指令多线程,就是让大量的线程执行同一个运算指令,只不过操作的是不同的数据。
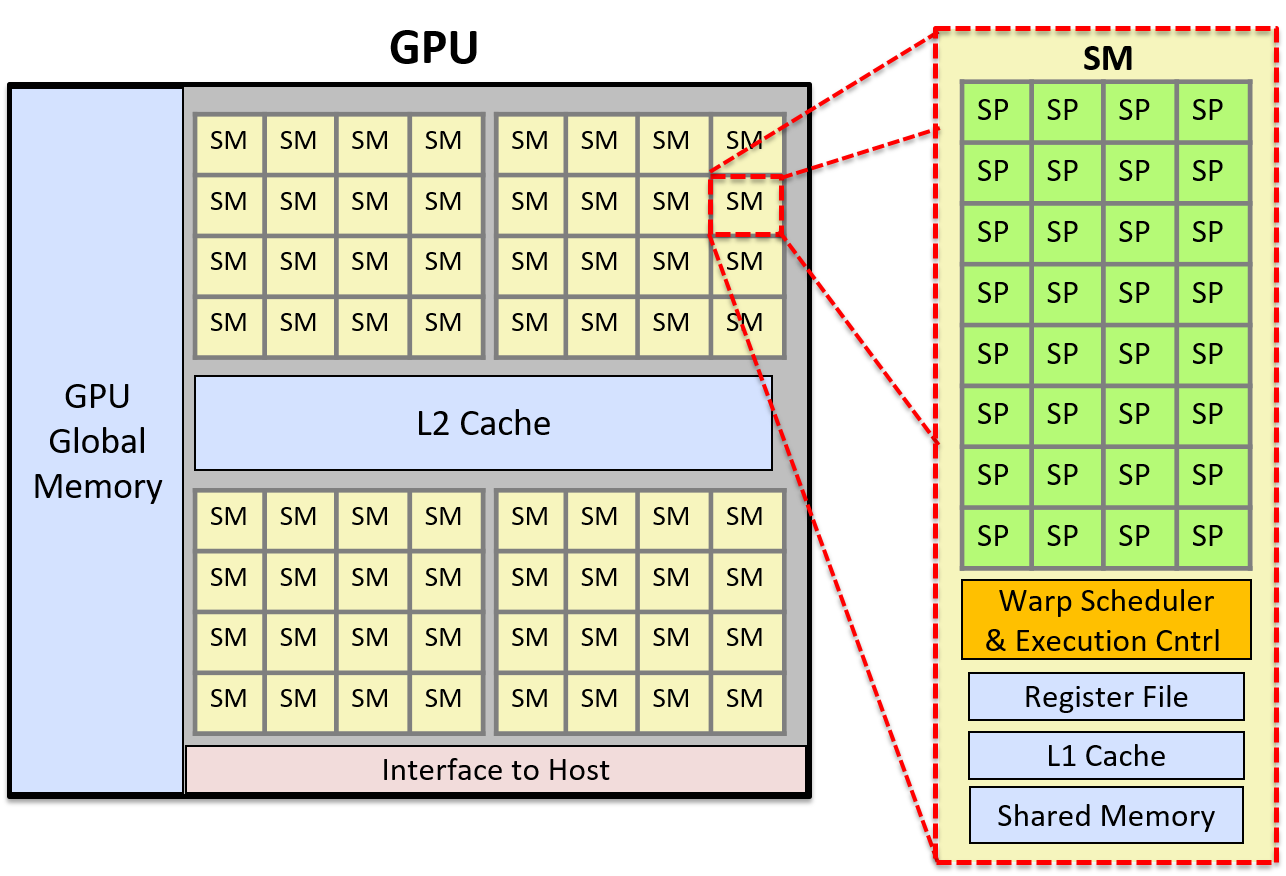
GPU的最小运算单元叫做SP(Streaming Processor),在新的架构中又叫CUDA Core,本质上是一个标量ALU(算术逻辑单元)。
多个CUDA Core组成一个SM(Streaming Multiprocessor,流式多处理器)。不同架构的SM拥有不同数量的CUDA Core。CUDA Core专指单精度运算单元,处理的是FP32数据。除此之外,一个SM中还有双精度运算单元(DPU),处理FP64数据,以及特殊功能单元(SFU),处理特殊数学函数如sin, cos, log, sqrt等,还有张量核心(Tensor Core)。
SM中除了这些元件外,还包括寄存器、共享内存、Warp调度器。为了理解这些元件的关系,我们从线程的结构讲起。
线程:Thread, Warp, Block和Grid
GPU是SIMT模型,也就是说,对于一个指令,会拆分成多个线程(thread),每个线程跑在CUDA Core上(这里和CPU是相似的),同一时间一个线程跑在一个CUDA Core上。然而,GPU不直接操作thread,而是把32个thread打包成一个Warp(线程束)。Warp是GPU硬件调度与执行的最小单位,也就是说,一条指令必须分配32的倍数个线程,每个Warp内的线程
多个Warp可以组成一个Thread Block(线程块,简称Block),这个线程块是在软件视角下的一个逻辑结构。一个Block包含若干个线程,这些线程会自动被切割为若干个Warp,例如如果定义的Block大小是128,那么就会被分为4个Warp。每个Block被分配给一个SM,这个Block的整个生命周期就在这个SM上度过,但是一个SM可以有一个或多个Block,只要SM的寄存器和共享内存够用。
然而,SM的执行单元是不认识Block的,它只认识Warp。SM会维护一个就绪队列,由Warp调度器来调度Warp,如果一个Warp就绪并且有足够的空闲CUDA Core,调度器就会把Warp交给CUDA Core执行。
那么Block的意义是什么呢?尽管SM的执行单元只调度Warp,但是SM的控制单元是认识Block的,它会为每个Block分配单独的一片共享内存,这片内存在Block内是共享的,但是和其他Block是隔离的。Block的存在意义就是为了更好地做线程同步。
从CUDA编程的角度,一个Block是一个线程的“三维容器”,可以看作是一个三维数组,它的维度用dim3结构来定义,例如:
1 | // 一维Block |
这里block的不同维度其实只是为了语义上易读,类似CPU中的N维数组,虽然看起来是N维的,但是事实上是按照1维展开寻址的。
而一个“核函数“启动的所有block的集合就称为一个Grid。
CUDA编程
CUDA是基于C++的扩展,在C++的基础上,引入了一些特殊关键字和类/结构/函数。为了让指令在GPU上运行,我们需要写一个核函数,并且用Host代码也就是CPU代码来调用这个核函数,类似一个系统调用。
从最简单开始,我们先写一个A+B的函数:将A、B数组按位相加并写入数组C。
头文件依赖
1 |
编写Kernel(核函数)
要放到CUDA Core(核)上运行的函数就是核函数。
1 | __global__ void vectorAdd(const float *A, const float *B, float *C, int length){ |
解读一下:
1 | __global__ void vectorAdd(const float *A, const float *B, float *C, int length); |
这里的__global__关键字是CUDA核函数的专用关键字,用于告知编译器这个函数由CPU调用,在GPU上执行。
1 | int idx = blockDim.x * blockIdx.x + threadIdx.x; |
这行代码就有意思了。这个核函数不是会分为多个线程执行吗,每个线程就只操作数组中的一位。那么每个线程的编号就是它前面的所有Block的所有线程数加上它在当前Block中的位置。想象我们在二维数组中给每个元素编号,是不是这样:
1 | int idx = i * N + j; |
这里是类似的道理,blockDim.x是每个Block容器的大小,blockIdx是当前Block的索引,threadIdx.x是当前线程在Block中的索引。当然这里只考虑比较简单的一维情况,更高维度的情况会在后续章节中讨论。
编写Main函数
现在我们写好了要在GPU上运行的Kernel,但是这个Kernel怎么调用呢?因此我们还需要写一个Main函数(Host代码)调用它。
1 | int main(){ |
这段代码还算比较清晰明了,唯一要注意的是启动核函数那里:
1 | vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(c_A, c_B, c_C, numElements); |
这个是一个固定格式:函数名<<<Grid数, Block数>>>(参数...),这里的blocksPerGrid会被写入到一个**只读特殊寄存器(SREG)**中,这样在核函数中取blockDim,就是去读这个寄存器。如果blocksPerGrid被定义为int,就等价于定义为一个一维的dim3对象。如果想要多维的block,就可以定义:dim3 blockSize(16, 16);并在vectorAdd中传入这个参数。这个我们后面会再遇到的。
至此我们就写完了最简单的一个CUDA程序。
CUDA编程 1. GPU架构和入门程序
install_url to use ShareThis. Please set it in _config.yml.